The Binomial Distribution
binomdist.RmdThe binomial distribution is the key to exact inference about a proportion. The purpose of this vignette is to explain the binomial distribution and provide some examples of practical uses for this distribution. This will pave the way for later learning about how the binomial distribution can be used for exact inference, including both hypothesis testing and confidence interval construction.
Required packages
The nplearn package is required for this vignette. All other functions used are in the base package.
Joint Events
Multiple independent events that occur are referred to as joint events. The total number of possible joint outcomes of a joint event is the product of the number of potential outcomes of each separate event. For example, on a five-item multiple choice quiz, where each question has four options, the number of possible patterns of responses is the product of five fours.
4*4*4*4*4
#> [1] 1024We can write this as an exponent.
4^5
#> [1] 1024We know from the laws of probability that if each event is independent, the probability of a specific set of joint events is equal to the product of the probability of the individual events. In our multiple-choice quiz example, here is the probability of a test taker getting a perfect score just by guessing.
(1/4)*(1/4)*(1/4)*(1/4)*(1/4)
#> [1] 0.0009765625Here it is written another way.
(1/4)^5
#> [1] 0.0009765625Here it is written yet another way.
0.25^5
#> [1] 0.0009765625Suppose we have a series of Bernoulli events. For example, suppose that we again administer a five-question quiz, but this time the items are true-false. This is a series of Bernoulli events because there are only two possible outcomes for each event. Here is the probability of getting a perfect score just by guessing.
0.5^5
#> [1] 0.03125A more sophisticated test taker will actually have studied for the test, so this test taker will not just be guessing. We could think of the probability of success on an item as a function of this person’s knowledge after learning the content. Here is the probability of a perfect score if the probability of success on each item is 0.7.
0.7^5
#> [1] 0.16807Let’s see what the chance of a perfect score is for someone who is very well prepared so that the success rate for each item is 0.95.
0.95^5
#> [1] 0.7737809Of course all of this is making the unrealistic assumption that the rate of success is the same for every item. In fact, so items are more difficult than others, so the actual probability of a perfect score might be something more like this.
0.8*0.95*0.75*0.95*0.70
#> [1] 0.37905This kind of test-taking discussion with different item difficulties is best left for a measurement course, such as item response theory. We will step out of the test-taking domain in a bit, but for now let’s proceed with this example and the (unrealistic) assumption that each item has the same difficulty level.
Permutations
Suppose I’m not just interested in a perfect score, but I’m also interested in questions like, what is the chance of obtaining four out of five correct on this true-false quiz if the probability of success for each item is 0.7? This is a bit tricky, because we don’t know which item the person will get wrong. Here is the probability of getting just the first item wrong.
0.3*0.7*0.7*0.7*0.7
#> [1] 0.07203Here it is written another way.
0.7^4 * 0.3^1
#> [1] 0.07203What about the probability of getting just the second item wrong?
0.7*0.3*0.7*0.7*0.7
#> [1] 0.07203The probability is the same! In fact, we could still write it this way.
0.7^4 * 0.3^1
#> [1] 0.07203It is pretty easy to figure out that there are five possible ways for the test taker to get just one item wrong on a five-item test: The first one could be wrong, the second item could be wrong, and so on. Thus, the total probability of getting any one item wrong is calculated this way.
5 * 0.7^4 * 0.3^1
#> [1] 0.36015That was straightforward, but it becomes more difficult with different numbers of items correct and different numbers of items. For example, how many different patterns will there be for three items correct and two items incorrect? What about if there are 10 items instead of five? How many patterns will there be for four items correct and six incorrect? Clearly these questions are not as easy to answer. What we need are some counting rules. Many nonparametric statistics are based on working with discrete values, so we often need to count. Methods of counting for various situations are an important component of nonparametric analysis.
The first counting rule is about permutations. A permutation of objects is a distinct ordering of objects. We can calculate the number of permutations of N objects with a product known as a factorial. For example, for five objects we use 5! (read as, five factorial).
5 * 4 * 3 * 2 * 1
#> [1] 120R includes a factorial function.
factorial(5)
#> [1] 120A side note: What do we do with 0!? By definition, 0! = 1.
factorial(0)
#> [1] 1The Binomial Coefficient
In our true-false quiz example we had five questions, so the number of possible permutations of the answers is 5! = 120. Yet if we want to know how many ways there are to get two incorrect answers out of the five questions, we really only care about two incorrect and three correct answers, regardless of where they occur. That is, we consider all incorrect answers as indisitinguishable from one another. There are only two distinct type of answers here: correct and incorrect. The permutation of wrong, wrong, right, right, right does not need to be considered different than the permutation of wrong, right, right, right, wrong.
To calculate how many permutations there are when we include identical “objects” (we consider every “right” and every “wrong” as identical) we need to divide the total number of permutations by the number of permutations of each identical object. Here’s the calculation for five true-false items when three are correct and two are incorrect.
This can be extended to any number of identical objects. The case where we have only two identical objects is all we will need when looking at a series of Bernoulli events, because by definition a Bernoulli event only has one of two outcomes. Given this case is so special, there is a special expression for it, as well as a special function for it. When we want to know how many ways we can get three items correct out of five Bernoulli trials, we say five choose three. Here is how we represent it.
\(\binom{5}{3}\)
Here’s the R function.
choose(5, 3)
#> [1] 10This function is referred to as the binomial coefficient. In general, we represent the number of ways that we can have \(x\) successes in \(n\) trials like this, which we read as n choose x.
\(\binom{n}{x}\)
It would seem quite difficult to figure how many different ways there are to obtain 13 correct answers on a 20-item true-false quiz, but the binomial coefficient function makes it easy.
choose(20,13)
#> [1] 77520The Binomial Probability Function
If we combine the concepts of joint events with the binomial coefficient, we can answer an interesting question. When we observe \(n\) independent Bernoulli events, each with the same probability of success, \(\pi\), what is the probability that \(x\) of these events will be a success? If that doesn’t really sound very interesting to you, consider a few examples.
If the chance of contracting an illness is 40% when coming into contact with another person with the illness, what is the probability that all six people who came into contact with an ill person will avoid aquiring the illness themself?
Suppose that there is an expensive treatment for the above illness and that medical professionals purchased enough drugs to treat two patients in anticipation that two of the six people will contract the illness. What is the probability that exactly two of the six people will indeed contract the illness?
If the overall pass rate on an entrance exam is 70%, what is the probability that we will be able to fill eight slots with successful examinees if there are 11 applicants for the position?
As we will see in the next vignette, knowing the probability of \(x\) successes in \(n\) trials can also be used to conduct hypotheses tests and construct confidence intervals for a proportion, so the value of being able to calculate probabilities based on \(n\) Bernoulli events goes beyond answering questions like those above.
Recall that we calculate the probability of independent joint events by taking the product of the probability of each event. When there is a 70% chance of passing an item on a five-item quiz, we calculate the probability of getting the first three items correct but missing the two remaining items like this.
0.7^3 * 0.3^2
#> [1] 0.03087In more general terms, the chance of getting the first \(x\) items correct but missing the remaining items on an \(n\)-item quiz when the probability of success is \(pi\) is calculated like this.
\(\pi^x (1-\pi)^{(n-x)}\)
That is, we multiply the probability of the \(x\) successes by the probability of the \(n-x\) failures.
I can’t think of a reason why I would want to know the chance of getting the first three items correct and missing the last two, but I can think of why I might want to know the probability of missing any two, not just the last two. That is where the binomial coefficient comes in handy. The binomial coefficient tells us how many ways we can arrange \(x\) successes in \(n\) trials. Here is how many ways we can have exactly three items correct on a five-item quiz.
choose(5, 3)
#> [1] 10If I multiply the probability of one specific sequence of three correct and two wrong with the number of ways I can have three correct and two wrong, that will give me the probability of obtaining any three correct on a five-item quiz.
choose(5, 3) * 0.7^3 * 0.3^2
#> [1] 0.3087We can right this in general terms like this.
\(P(X = x) = \binom{n}{x}\pi^x (1-\pi)^{(n-x)}\)
This is the binomial probability function. It tells us the probability of \(x\) successes in \(n\) Bernoulli events when the probability of success is \(\pi\) for each Bernoulli event. Note that whereas the values of \(x\) are either 0 or 1 for a Bernoulli event, the values of \(x\) for the binomial function will range from 0 to \(n\). That is, you can have 0 success, 1 success, 2 successes, and so on, all the way up to \(n\) successes.
Let’s now answer the first two of our three questions.
If the chance of contracting an illness is 40% when coming into contact with another person with the illness, what is the probability that all six people who came into contact with an ill person will avoid aquiring the illness themself?
Here’s the formula that will provide the solution.
\(P(X = 0) = \binom{6}{0}0.4^0 (1-0.4)^{(6-0)}\)
Here it is calculated in R.
choose(6, 0)*0.4^0*(1-0.4)^(6-0)
#> [1] 0.046656It looks like there is a very high chance that someone will get sick! The second question is about the anticipation that this will be two people.
Suppose that there is an expensive treatment for the above illness and that medical professionals purchased enough drugs to treat two patients in anticipation that two of the six people will contract the illness. What is the probability that exactly two of the six people will indeed contract the illness?
Here’s the formula that will provide the solution.
\(P(X = 2) = \binom{6}{2}0.4^2 (1-0.4)^{(6-2)}\)
Here it is calculated in R.
choose(6, 2)*0.4^2*(1-0.4)^(6-2)
#> [1] 0.31104So there is about a one in three chance that the medical staff purchased exactly the correct amount of drugs. It is probably more reasonable to believe that the medical staff wants to make sure they have enough drugs, but it would be OK to have some left over. This leads us to the most common use of the binomial probability function, which is the creation of the binomial distribution.
The Binomial Distribution
Rather than calculating the probability that zero or two people will get sick when they come in contact with a particular bacteria or virus, wouldn’t it make sense to know the probability for every possible outcome? Yes! That is what we do to create the binomial distribution. Here are all the probabilities.
n <- 6
x <- 0:n
pi <- 0.4
prob.x <- choose(n, x)*pi^x*(1-pi)^(n-x)
cbind(x,prob.x)
#> x prob.x
#> [1,] 0 0.046656
#> [2,] 1 0.186624
#> [3,] 2 0.311040
#> [4,] 3 0.276480
#> [5,] 4 0.138240
#> [6,] 5 0.036864
#> [7,] 6 0.004096Given that we calculated the probability for every possible outcome, these better add to one!
sum(prob.x)
#> [1] 1They do! Here’s a picture of the binomial distribution. Note that it relates every possible value of \(x\) to the probability of observing \(x\) in \(n\) trials, so this is a probability function.
binom_plot(6, 0.4)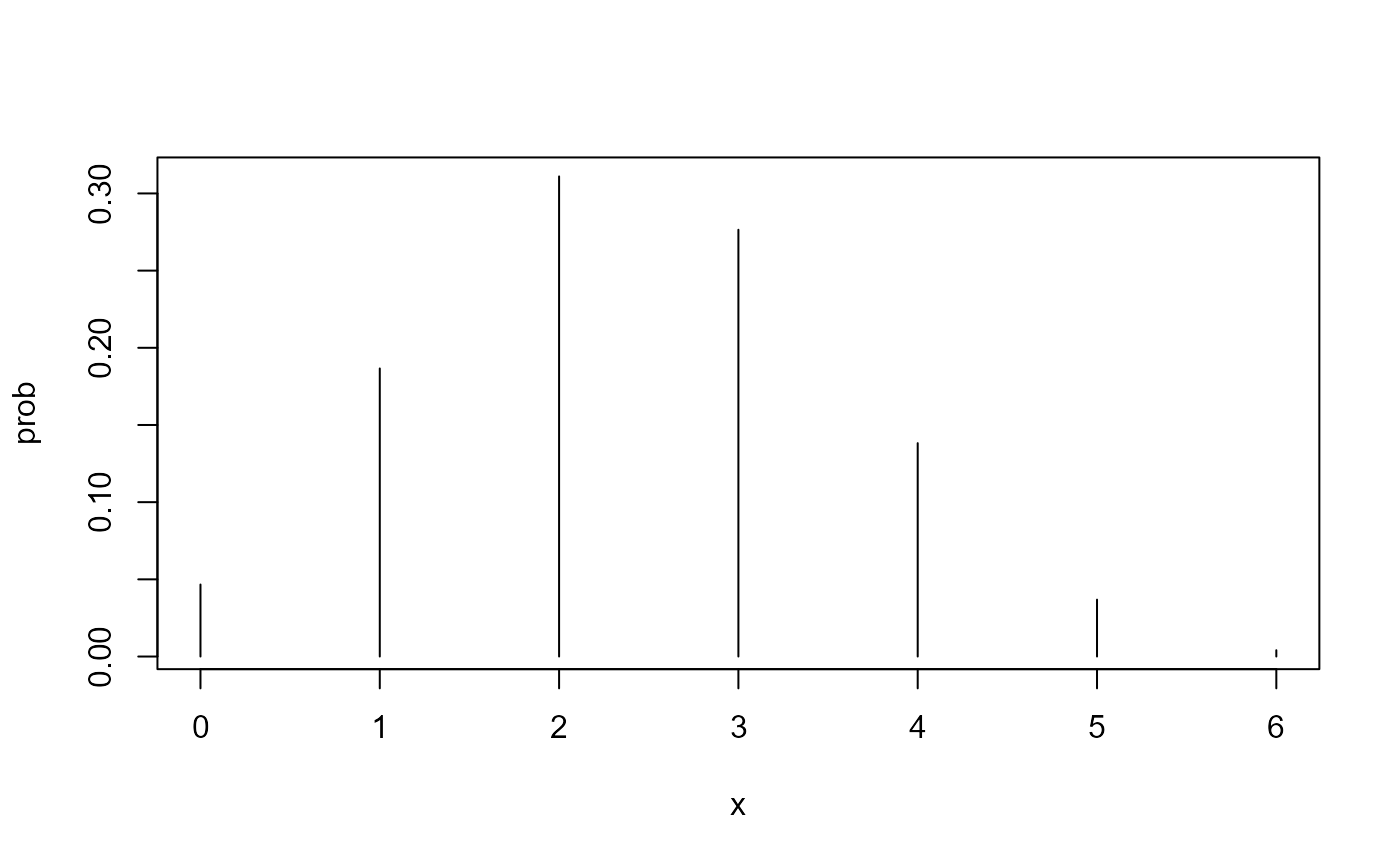
If we want to determine the probability that we have enough drugs for up to two people who may get sick (rather than exactly two people), we can find the cumulative probability up to and including two.
There’s a little better than a one in two chance that two doses will be enough. (If this is a serious disease, I would want a higher probability that I’m going to be able to treat everyone!)
You may have guessed by now that we don’t really need to write R code to make these calculations because someone has already done it for us. You would be correct. The binomial distribution is a common distribution, so we have the d, p, q, and r distribution functions at our disposal. Yay!
Here’s the probability that exactly two out of six people will contract the sickness.
dbinom(x = 2, size = 6, prob = 0.4)
#> [1] 0.31104Here’s the probability that two or less persons out of six people will contract the sickness.
pbinom(2, 6, 0.4)
#> [1] 0.54432Suppose we want to be at least 80% certain that we have enough treatments. How many should we get?
qbinom(0.8, 6, 0.4)
#> [1] 3We need three treatments. Remember that this is a discrete distribution, so it would be unusual to have the cumulative probability up to, and including, three be exactly 80%. Let’s see what it is.
pbinom(3, 6, 0.4)
#> [1] 0.8208It is 82%. Remember the rule for quantiles of a discrete distribution. We are seeking the smallest value of \(x\) on the distribution such that the cumulative probability to, and including, \(x\) is at least the specified probability. That’s what we got here, and we were able to use this rule to our advantage by being at least 80% sure that we have enough treatments.
Let’s consider the final question posed above.
If the overall pass rate on an entrance exam is 70%, what is the probability that we will be able to fill eight slots with successful examinees if there are 11 applicants for the position?
If we have eight or more successful examinees, we will be able to fill the eight slots. We could do this one of two ways. We could calculate the probability of seven or fewer successes and then subtract this from one.
1 - pbinom(7, 11, 0.7)
#> [1] 0.5695623Alternatively, we could calculate the upper tail.
pbinom(7, 11, 0.7, lower.tail = FALSE)
#> [1] 0.5695623The important trick to remember here is that if we want an upper tail that includes a specified value (in this case, the value of eight), we need to subtract one from this value to make sure it is included in the upper region of the distribution.
Finally, suppose we wanted to do a simulation using the binomial distribution. Here are 20 random draws from a distribution with \(\pi\) = 0.8 when the sample size is 15.
rbinom(20, 15, 0.8)
#> [1] 11 12 12 13 13 12 14 11 10 14 11 15 12 12 11 13 13 12 11 15Keep in mind that what each number we are randomly generating is the value of \(x\), which is the number of successes in \(n\) trials. In this example there are 15 opportunities for success. The probability of success is quite high, so we are primarily seeing high numbers of successes out of the 15 trials.
In this example, we were drawing from a binomial distribution with \(n\) trials and a probability of success, \(\pi\). These are the parameters of the binomial distribution. Any binomial distribution can be generated if we know these two parameters. Let’s end with a picture of a binomial distribution when \(n\) = 100 and \(\pi\) = 0.5.
binom_plot(100, 0.5)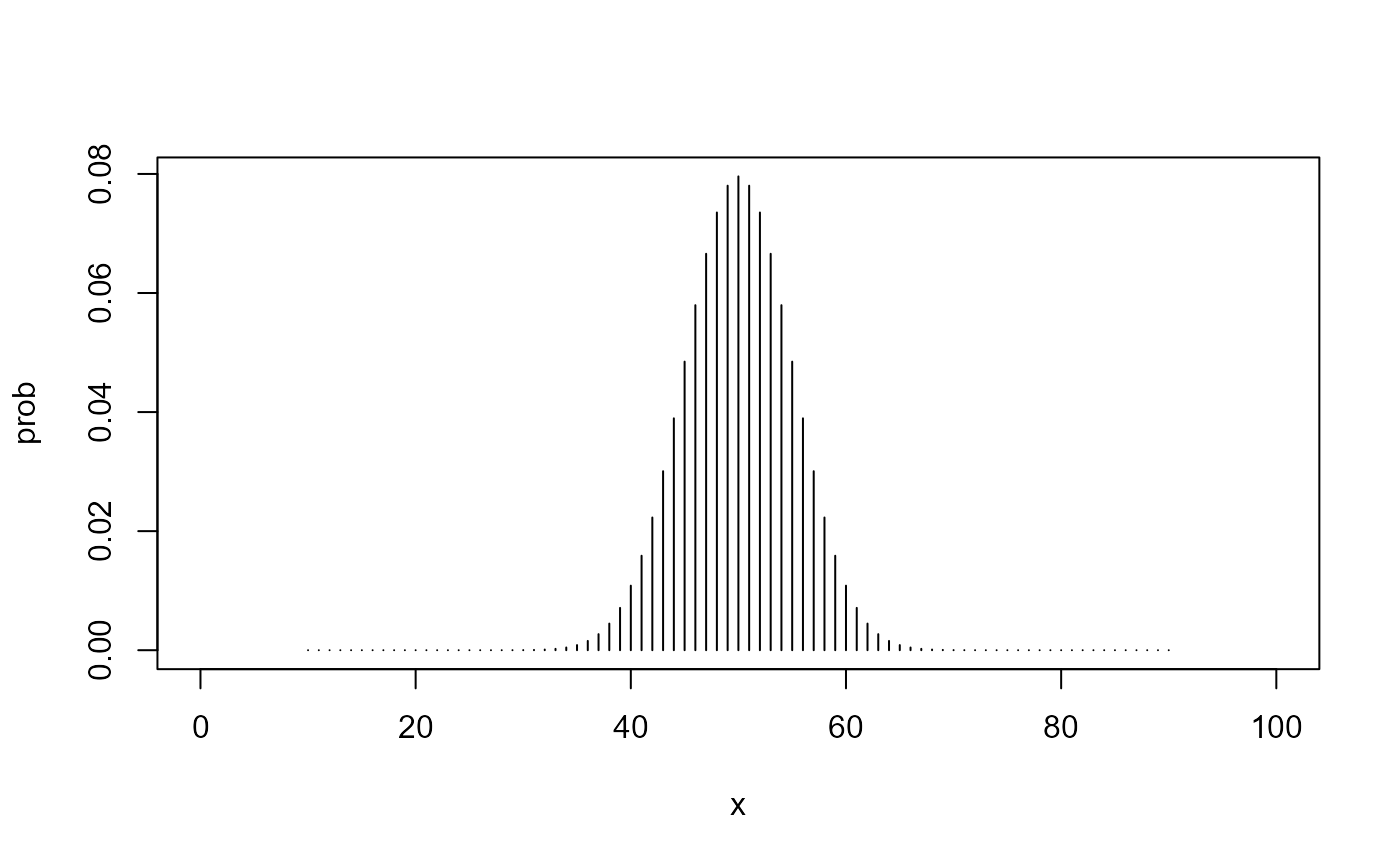
That looks like a normal distribution, doesn’t it? That is why we can use the normal distribution for a large-sample approximation and it works pretty well. Yet the above distribution is not normal. For one thing, it is a discrete distribution, rather than continuous. So why bother to use a continuous distribution to approximate results when we can use the actual distribution? I have no idea! In the next vignette, let’s make inferences using the actual distribution, thus calculating exact probabilities rather than approximations.